 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified and Reproducible Experimentation Framework for Speech Understanding
May 29, 2026Speech foundation models and Speech LLMs have advanced speech understanding, yet deployment-oriented model selection is hindered by non-comparable evaluations caused by mismatched post-processing, and by training results that are hard to reproduce across data scales and pipelines. We present SURE, a unified experimentation framework that standardizes prediction formats, normalization, and scoring. SURE evaluates strong systems across paradigms, from conventional pipelines to Speech LLMs, on representative tasks under realistic acoustic and linguistic stressors. Beyond evaluation, SURE introduces an agent-assisted training conversion flow that maps paper and code into versioned, runnable training pipelines under a unified protocol on matched open-data subsets. Overall, SURE improves comparability and reproducibility for deployment-oriented evaluation.
Audio-Mind: An Auditable Agentic Framework for Audio Understanding
May 27, 2026Audio agents extend large audio-language models (LALMs) by decomposing audio questions into tool calls, intermediate evidence, and iterative reasoning steps. However, as LALMs become stronger, the key challenge shifts from enabling tool use to determining when agentic evidence acquisition genuinely benefits audio understanding. We propose Audio-Mind, an auditable and pluggable framework for conditional evidence acquisition in audio understanding. Audio-Mind dynamically combines a strong frontend with planner-guided tool use, preserving frontend judgment when initial evidence is sufficient while acquiring bounded external evidence for questions with unresolved evidence gaps. Experiments on MMAR and MSU-Bench show that Audio-Mind outperforms prior audio-agent baselines, reaching 80.4% accuracy on MMAR and 82.8% accuracy on MSU-Bench. A matched-backbone comparison highlights why this design matters: under strong audio frontends, agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment. Beyond accuracy, Audio-Mind produces higher-quality, auditable reasoning traces that expose uncertainty, tool evidence, and answer rationales, offering a potential basis for more reliable audio-QA annotation and error analysis.
TASU2: Controllable CTC Simulation for Alignment and Low-Resource Adaptation of Speech LLMs
Apr 09, 2026Speech LLM post-training increasingly relies on efficient cross-modal alignment and robust low-resource adaptation, yet collecting large-scale audio-text pairs remains costly. Text-only alignment methods such as TASU reduce this burden by simulating CTC posteriors from transcripts, but they provide limited control over uncertainty and error rate, making curriculum design largely heuristic. We propose \textbf{TASU2}, a controllable CTC simulation framework that simulates CTC posterior distributions under a specified WER range, producing text-derived supervision that better matches the acoustic decoding interface. This enables principled post-training curricula that smoothly vary supervision difficulty without TTS. Across multiple source-to-target adaptation settings, TASU2 improves in-domain and out-of-domain recognition over TASU, and consistently outperforms strong baselines including text-only fine-tuning and TTS-based augmentation, while mitigating source-domain performance degradation.
Dynamic Quadrupedal Legged and Aerial Locomotion via Structure Repurposing
Oct 10, 2025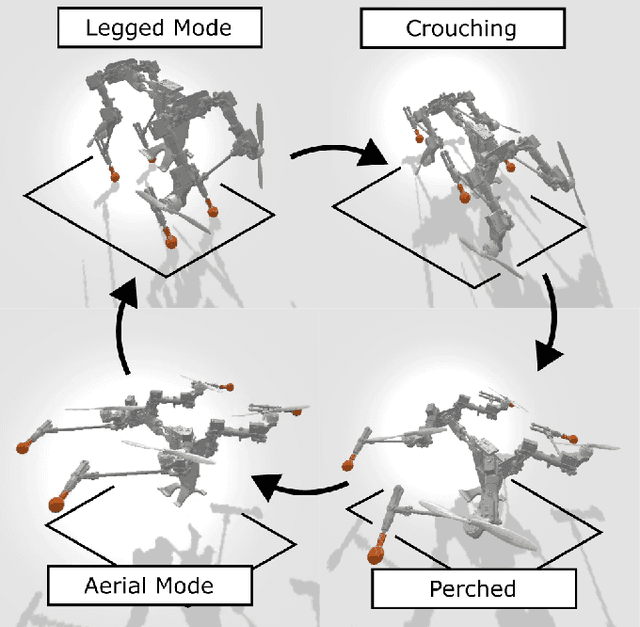
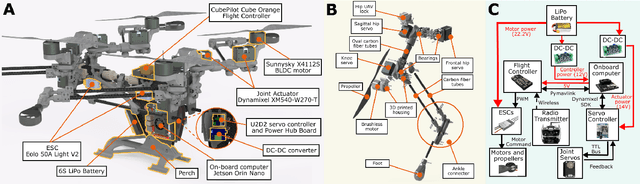

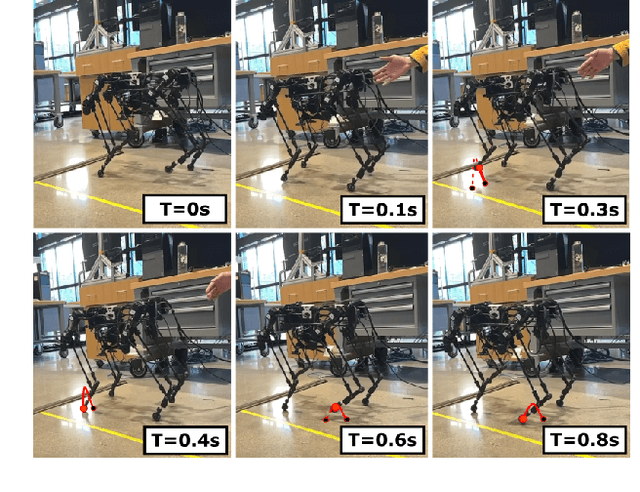
Multi-modal ground-aerial robots have been extensively studied, with a significant challenge lying in the integration of conflicting requirements across different modes of operation. The Husky robot family, developed at Northeastern University, and specifically the Husky v.2 discussed in this study, addresses this challenge by incorporating posture manipulation and thrust vectoring into multi-modal locomotion through structure repurposing. This quadrupedal robot features leg structures that can be repurposed for dynamic legged locomotion and flight. In this paper, we present the hardware design of the robot and report primary results on dynamic quadrupedal legged locomotion and hovering.
Guiding Energy-Efficient Locomotion through Impact Mitigation Rewards
Oct 10, 2025Animals achieve energy-efficient locomotion by their implicit passive dynamics, a marvel that has captivated roboticists for decades.Recently, methods incorporated Adversarial Motion Prior (AMP) and Reinforcement learning (RL) shows promising progress to replicate Animals' naturalistic motion. However, such imitation learning approaches predominantly capture explicit kinematic patterns, so-called gaits, while overlooking the implicit passive dynamics. This work bridges this gap by incorporating a reward term guided by Impact Mitigation Factor (IMF), a physics-informed metric that quantifies a robot's ability to passively mitigate impacts. By integrating IMF with AMP, our approach enables RL policies to learn both explicit motion trajectories from animal reference motion and the implicit passive dynamic. We demonstrate energy efficiency improvements of up to 32%, as measured by the Cost of Transport (CoT), across both AMP and handcrafted reward structure.
Elevating Legal LLM Responses: Harnessing Trainable Logical Structures and Semantic Knowledge with Legal Reasoning
Feb 11, 2025



Large Language Models (LLMs) have achieved impressive results across numerous domains, yet they experience notable deficiencies in legal question-answering tasks. LLMs often generate generalized responses that lack the logical specificity required for expert legal advice and are prone to hallucination, providing answers that appear correct but are unreliable. Retrieval-Augmented Generation (RAG) techniques offer partial solutions to address this challenge, but existing approaches typically focus only on semantic similarity, neglecting the logical structure essential to legal reasoning. In this paper, we propose the Logical-Semantic Integration Model (LSIM), a novel supervised framework that bridges semantic and logical coherence. LSIM comprises three components: reinforcement learning predicts a structured fact-rule chain for each question, a trainable Deep Structured Semantic Model (DSSM) retrieves the most relevant candidate questions by integrating semantic and logical features, and in-context learning generates the final answer using the retrieved content. Our experiments on a real-world legal QA dataset-validated through both automated metrics and human evaluation-demonstrate that LSIM significantly enhances accuracy and reliability compared to existing methods.
Enhanced Capture Point Control Using Thruster Dynamics and QP-Based Optimization for Harpy
Nov 21, 2024Our work aims to make significant strides in understanding unexplored locomotion control paradigms based on the integration of posture manipulation and thrust vectoring. These techniques are commonly seen in nature, such as Chukar birds using their wings to run on a nearly vertical wall. In this work, we developed a capture-point-based controller integrated with a quadratic programming (QP) solver which is used to create a thruster-assisted dynamic bipedal walking controller for our state-of-the-art Harpy platform. Harpy is a bipedal robot capable of legged-aerial locomotion using its legs and thrusters attached to its main frame. While capture point control based on centroidal models for bipedal systems has been extensively studied, the use of these thrusters in determining the capture point for a bipedal robot has not been extensively explored. The addition of these external thrust forces can lead to interesting interpretations of locomotion, such as virtual buoyancy studied in aquatic-legged locomotion. In this work, we derive a thruster-assisted bipedal walking with the capture point controller and implement it in simulation to study its performance.
Conjugate momentum based thruster force estimate in dynamic multimodal robot
Nov 21, 2024In a multi-modal system which combines thruster and legged locomotion such our state-of-the-art Harpy platform to perform dynamic locomotion. Therefore, it is very important to have a proper estimate of Thruster force. Harpy is a bipedal robot capable of legged-aerial locomotion using its legs and thrusters attached to its main frame. we can characterize thruster force using a thrust stand but it generally does not account for working conditions such as battery voltage. In this study, we present a momentum-based thruster force estimator. One of the key information required to estimate is terrain information. we show estimation results with and without terrain knowledge. In this work, we derive a conjugate momentum thruster force estimator and implement it on a numerical simulator that uses thruster force to perform thruster-assisted walking.
Quadratic Programming Optimization for Bio-Inspired Thruster-Assisted Bipedal Locomotion on Inclined Slopes
Nov 20, 2024



Our work aims to make significant strides in understanding unexplored locomotion control paradigms based on the integration of posture manipulation and thrust vectoring. These techniques are commonly seen in nature, such as Chukar birds using their wings to run on a nearly vertical wall. In this work, we show quadratic programming with contact constraints which is then given to the whole body controller to map on robot states to produce a thruster-assisted slope walking controller for our state-of-the-art Harpy platform. Harpy is a bipedal robot capable of legged-aerial locomotion using its legs and thrusters attached to its main frame. The optimization-based walking controller has been used for dynamic locomotion such as slope walking, but the addition of thrusters to perform inclined slope walking has not been extensively explored. In this work, we derive a thruster-assisted bipedal walking with the quadratic programming (QP) controller and implement it in simulation to study its performance.
Optimization free control and ground force estimation with momentum observer for a multimodal legged aerial robot
Nov 18, 2024



Legged-aerial multimodal robots can make the most of both legged and aerial systems. In this paper, we propose a control framework that bypasses heavy onboard computers by using an optimization-free Explicit Reference Governor that incorporates external thruster forces from an attitude controller. Ground reaction forces are maintained within friction cone constraints using costly optimization solvers, but the ERG framework filters applied velocity references that ensure no slippage at the foot end. We also propose a Conjugate momentum observer, that is widely used in Disturbance Observation to estimate ground reaction forces and compare its efficacy against a constrained model in estimating ground reaction forces in a reduced-order simulation of Husky.